
El problema siempre es de negocio, no técnico#
Los que me conocéis me oiréis decir muchas veces que la tecnología es un medio para un fin. En un negocio de consultoría con un elevado componente de soporte técnico, cada ticket es artesanal, es decir, un nuevo puzzle en el que empiezas desde la casilla cero. Un arquitecto cloud recibe un caso, abre algunos terminales, lanza varios comandos con el CLI del cloud provider de turno, cruza datos con la plataforma interna, y produce un diagnóstico más o menos preciso del problema que está tratando. Es un trabajo de alto valor, y requiere de mucho contacto pues el contexto del cliente es muy relevante. Sin embargo, tiene un problema: escala linealmente con las personas. Cada arquitecto nuevo supone un coste fijo muy elevado y además, cada arquitecto que se va se lleva conocimiento con él.
La pregunta que me hice no fue “¿cómo automatizo esto?” sino algo más sutil: ¿cómo hago que cada arquitecto tenga un ejército de minions que le haga el trabajo pesado de investigación, para que él se centre en lo que realmente aporta valor? Esa distinción importa, porque no estamos hablando de reemplazar personas sino de apalancarlas con tecnología, el famoso ingeniero centauro. Y esto, en una empresa de servicios, tiene un impacto directo en la valoración de la compañía porque estás desacoplando la generación de valor de la contratación de headcount.

La decisión contrarian: no construyas un agente, reutiliza uno#
Como buen friki, mi instinto natural fue tirarme a picar el código. Montar un agent loop desde cero con algún framework tipo ADK de Google, implementar tool calling, gestión de memoria, conectar MCPs y un largo etcétera. Pero como también soy ingeniero, y como decía un profesor en la universidad, y por tanto un vago, me paré a pensar y me di cuenta de algo que casi nadie en el ecosistema actual está diciendo: ¿por qué construir un agente con Claude Code, si Claude Code ya es uno?
Claude Code (o Gemini CLI, o herramientas similares) ya resuelve el agent loop, la gestión de herramientas, la orquestación de llamadas, la interacción con MCP servers, extensión de capacidades con skills, la inversión de control con webhooks y otro largo etcétera, porque en al fin y al cabo, son productos maduros en los que equipos enteros de gente muy inteligente y con mucha financiación trabajan full time para mejorarlos. Yo iba a replicar todo eso… ¿para qué?. No tenía mucho sentido. Además, con mi mentalidad de producto, lo importante era mitigar el riesgo del valor, ¿cómo puedo poner algo delante de un cliente lo más rápido posible que le libere de su pain point?.
Por eso me decidí por esta aproximación de utilizar COTS (commercial off-the-shelf) e invertir mi tiempo en lo que de verdad importaba: la orquestación del contexto y el entorno, las credenciales, los playbooks de investigación y la integración con las herramientas internas de la empresa. En lugar de construir un agente desde cero, construí una metatoolkit cognitivo donde meter un agente que ya existía.
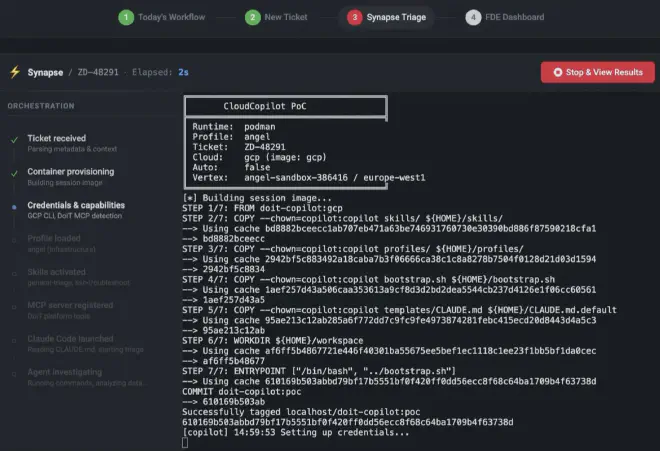
A estas alturas del post, os estaréis preguntando, en que se traduce esto en la práctica, pues eso se traduce en un Dockerfile donde se instala Claude Code como una dependencia npm más, un script de bootstrap que detecta qué herramientas tiene disponibles (CLI de cloud, MCP de la plataforma interna), filtra los skills de investigación según las capacidades del contexto, genera dinámicamente las instrucciones para el agente, y lo lanza. Todo el trabajo de orquestación está en un script en bash y en la propia estructura del contenedor, no en un framework de agentes.
Aquí es donde entra lo que, en mi humilde opinión, es la parte más interesante: la ingeniería de contexto. Meter Claude Code en un contenedor sin más no te da un agente para hacer el triage, te da un chatbot con acceso a una terminal. Lo que convierte esa caja en algo útil es el contexto que le inyectas. En mi caso, el bootstrap genera dinámicamente un CLAUDE.md adaptado a cada ticket: quién es el cliente, qué cloud usa, qué proyecto investigar, qué prioridad tiene, qué herramientas tiene disponibles, y cuál es el protocolo de triage que debe seguir según el modo en el que esté operando (completo, solo plataforma, o mínimo). Además, cada arquitecto tiene un perfil que define su especialidad y qué skills de investigación se le cargan, y esos skills a su vez declaran qué capacidades necesitan para funcionar, el bootstrap los filtra automáticamente. No es prompt engineering en el sentido clásico de “escribir un buen prompt”: es diseñar el entorno cognitivo completo en el que el agente opera. El prompt es solo una pieza; el contexto real incluye qué herramientas ve, qué playbooks tiene, y qué información del ticket y del cliente le llega ya estructurada.
--ticket ZD-48291 --cloud gcp --profile angel"] subgraph BUILD["Capas de imagen Docker"] direction TB BASE["Dockerfile.base
Node.js · Claude Code · DoiT MCP"] CLOUD["Dockerfile.gcp
Google Cloud SDK"] SESSION["Dockerfile
Skills · Profiles · Bootstrap"] BASE --> CLOUD --> SESSION end subgraph MOUNTS["Volúmenes montados"] direction LR CREDS["🔒 Credenciales :ro"] WORKSPACE["📁 Workspace persistente"] end RUN --> BUILD RUN --> MOUNTS subgraph CONTAINER["📦 Contenedor"] direction TB B1["1. Copiar credenciales :ro → /tmp/"] B2["2. Detectar capacidades
GCP ✓ · AWS ✓ · DoiT MCP ✓"] B3["3. Determinar modo
full | doit-only | minimal"] B4["4. Cargar perfil FDE
angel → infrastructure"] B5["5. Filtrar skills por capacidades"] B6["6. Generar CLAUDE.md dinámico"] B7["7. Registrar MCP servers"] B1 --> B2 --> B3 --> B4 --> B5 --> B6 --> B7 end BUILD --> CONTAINER MOUNTS --> CONTAINER B7 --> CLAUDE["🤖 Claude Code · Agente de triage"] subgraph TOOLS["Herramientas disponibles"] direction LR GCLOUD["gcloud"] AWSCLI["aws"] MCP["DoiT MCP"] SKILLS["Skills"] end subgraph OUTPUT["Output"] direction LR RAW["./raw/"] FINDINGS["./findings/"] REPORT["TRIAGE_REPORT.md"] end CLAUDE --> TOOLS CLAUDE --> OUTPUT
El concepto: minions desechables#
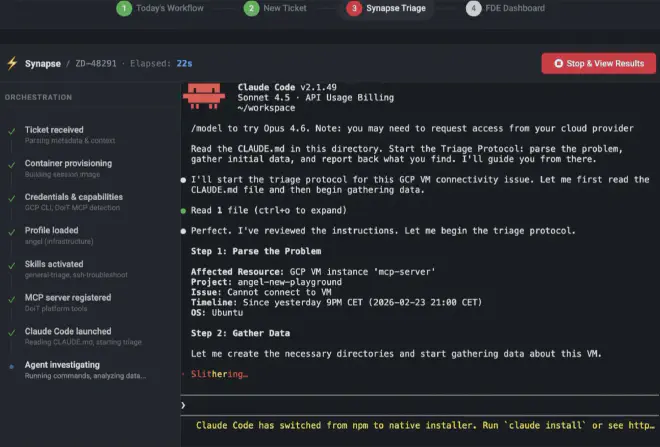
El resultado de toda esta vaina, es un contenedor inmutable que se levanta bajo demanda. Se le pasa el número de un ticket, credenciales de cloud en modo solo lectura, y las herramientas de Skills y MCP necesarias. El agente investiga: ejecuta comandos, consulta la plataforma, cruza datos, genera un informe de triage estructurado. Y cuando termina, el contenedor muere (o no, sigue leyendo y verás el plot twist).
En mi post sobre GizTUI hablé de la era del código desechable: herramientas que construyes, usas, y descartas. Lo que estamos hablando hoy en este post, es la evolución natural de esa idea: trabajadores cognitivos desechables. No es una metáfora rebuscada, es literalmente lo que pasa. Cada instancia es inmutable, efímera, y reproducible. Como un pod de Kubernetes, pero para trabajo intelectual.
Esto tiene unas propiedades muy interesantes a nivel operativo. La primera es homogeneidad: da igual qué arquitecto lance el contenedor, el entorno es idéntico, te apalancas en una tecnología que resuelve el problema de “en mi máquina funciona”. La IA puede ser no determinista en sus respuestas, pero con esta aproximación el entorno en el que opera es completamente controlado y reproducible. La segunda es la auditabilidad: todos los comandos ejecutados y sus outputs quedan registrados en el espacio de trabajo (workspace). La tercera es seguridad, y aquí hay una capa que merece mención aparte: las credenciales de investigación se montan en solo lectura y el agente solo tiene permisos de lectura sobre el entorno del cliente, pero además, Claude Code permite configurar cómo accedes al modelo que lo alimenta. En este caso, las llamadas al LLM se enrutan a través de Vertex AI de Google Cloud, lo que significa que los datos del cliente nunca tocan directamente la API del fabricante del modelo. Esto desacopla los datos de tus clientes del proveedor de IA y te brinda control total sobre la observabilidad y la telemetría: sabes exactamente qué se envía, cuántos tokens consume cada triage, y puedes auditar todo desde tu propia infraestructura, tomando acción cuando sea necesario. Y la cuarta es escalabilidad: si mañana tienes cincuenta tickets P1 a la vez, levantas cincuenta contenedores a la vez, y a correr.
Human in the loop: es diseño, no una limitación#
Creo que hay un detalle que no debe pasar desapercibido, y es que esto no está pensado para funcionar en piloto automático sin supervisión. El human in the loop no es una concesión al estado actual de la tecnología, que también, sino una decisión consciente de diseño. El agente hace el trabajo pesado de recopilación y análisis inicial, pero el arquitecto sigue tomando las decisiones. Revisa el informe, valida las hipótesis, decide los siguientes pasos.
Esto es intencionado porque el valor real del ingeniero no está en ejecutar gcloud compute instances describe, sino en interpretar lo que ve, cruzarlo con su experiencia, y proponer una solución al cliente. El minion le libera de las dos horas de arqueología para que se centre en los treinta minutos de criterio experto.
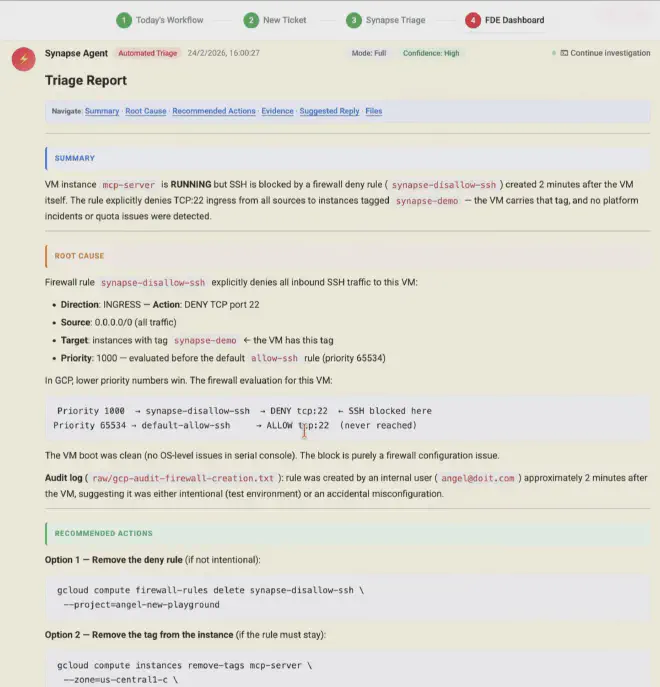
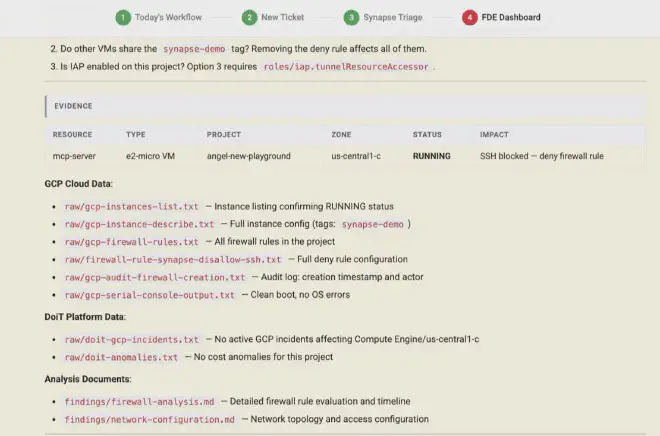
Y aquí llega el plot twist que comentaba más arriba, y es que hay un detalle que hace que el hand-off sea realmente limpio: el contenedor no tiene por qué morir cuando el agente termina su investigación. Puede quedarse esperando a que el arquitecto se conecte y retome la sesión exactamente donde el agente la dejó, con todo el contexto, los ficheros generados, y el hilo de razonamiento intacto. Claude Code permite hacer --resume sobre una sesión existente, así que el arquitecto entra, ve lo que el agente ha hecho, y puede pedirle que profundice en algo concreto o que investigue una hipótesis alternativa. Es como si el agente le hubiera dejado la mesa preparada con todas las piezas ordenadas. Y si no quieres mantener el contenedor original encendido, puedes persistir el fichero de sesión y bootstrapearlo en uno nuevo: el contexto viaja con el estado, no con la instancia.
Y entonces, ¿qué es lo que cambia?#
Si esto funciona, y esta primera versión sugiere que sí, lo que cambia no es solo la velocidad de triage. Lo que cambia es la estructura de costes de un negocio de servicios técnicos. Cada arquitecto pasa de gestionar X tickets al día a gestionar 3X o 5X, porque la parte mecánica de la investigación está delegada. No necesitas contratar al doble de personas para atender al doble de clientes. Y el conocimiento no se pierde cuando alguien se va, porque los playbooks de investigación viven en los skills del contenedor, no en la cabeza de nadie.
Cuando presenté esta idea en una sesión interna de IA que hacemos los jueves en DoiT, la reacción más interesante no vino de los ingenieros, a ellos les brillaban los ojos con la por***rafía técnica, sino de la gente de negocio, que inmediatamente vio las implicaciones en márgenes y escalabilidad.
La pregunta que queda abierta#
Todo esto lo monté como una prueba de concepto en dos o tres días, a ratos de unas pocas horas cada uno. Y creo que es importante ser honesto con lo que esto es y lo que no es: no es una solución completa lista para producción. Faltan piezas importantes, la gestión de credenciales efímeras con rotación automática, auditoría formal de las acciones del agente, seguridad ante prompt injection, rate limiting, evaluación sistemática de la calidad de los triajes, gestión de costes de tokens a escala, y un modelo de permisos más granular, entre otras cosas. Cada una de estas piezas tiene su propia complejidad y sus propias decisiones de diseño. Lo bueno es que en DoiT estamos trabajando para convertir esta visión en un producto real, así que si hay interés (y me lo demostrais :-p), las decisiones que tomemos serán material para futuros posts donde pueda contar cómo se aborda esa transición de POC a producción.
Sin embargo, la pregunta que quiero dejar encima de la mesa no es técnica. Es la siguiente: ¿y si el futuro del soporte técnico no es contratar más ingenieros, sino darle a cada ingeniero su propio ejército de minions desechables que hagan el trabajo pesado por él? Y si es así, ¿qué habilidades son las que van a importar de verdad en un ingeniero cuando la investigación mecánica la haga una máquina?
Eso es lo que mantiene mi cabeza ocupada. Si a ti también, hablemos.