
The problem is always business, not technical#
Those of you who know me will have heard me say many times that technology is a means to an end. In a consulting business with a strong technical support component, every ticket is artisanal—a new puzzle where you start from square one. A cloud architect receives a case, opens a few terminals, runs several commands with the relevant cloud provider’s CLI, cross-checks data with the internal platform, and produces a more or less accurate diagnosis of the issue at hand. It’s high-value work and requires a lot of contact because client context matters a great deal. But it has one drawback: it scales linearly with people. Each new architect is a very high fixed cost, and when someone leaves, they take knowledge with them.
The question I asked myself wasn’t “how do I automate this?” but something subtler: how do I give each architect an army of minions to do the heavy investigation work, so they can focus on what actually adds value? That distinction matters, because we’re not talking about replacing people but about leveraging them with technology—the famous centaur engineer. In a services company, that has a direct impact on how the company is valued, because you’re decoupling value creation from headcount.

The contrarian move: don’t build an agent, reuse one#
As a proper geek, my first instinct was to dive into code. Build an agent loop from scratch with some framework like Google’s ADK, implement tool calling, memory management, wire up MCPs, and so on. But I’m also an engineer, and as a professor of mine used to say, therefore lazy—so I stopped to think and realised something almost nobody in the current ecosystem is saying: why build an agent with Claude Code when Claude Code already is one?
Claude Code (or Gemini CLI, or similar tools) already handles the agent loop, tool management, call orchestration, MCP server interaction, capability extension via skills, control inversion with webhooks, and a long etc. They’re mature products with whole teams of very smart, well-funded people working full time to improve them. I was going to replicate all of that… for what? It didn’t make much sense. And with my product mindset, what mattered was mitigating value risk: how can I put something in front of a customer as fast as possible that relieves their pain point?
So I went with using COTS (commercial off-the-shelf) and investing my time in what really mattered: orchestrating context and environment, credentials, investigation playbooks, and integration with the company’s internal tools. Instead of building an agent from scratch, I built a cognitive meta-toolkit to drop an existing agent into.
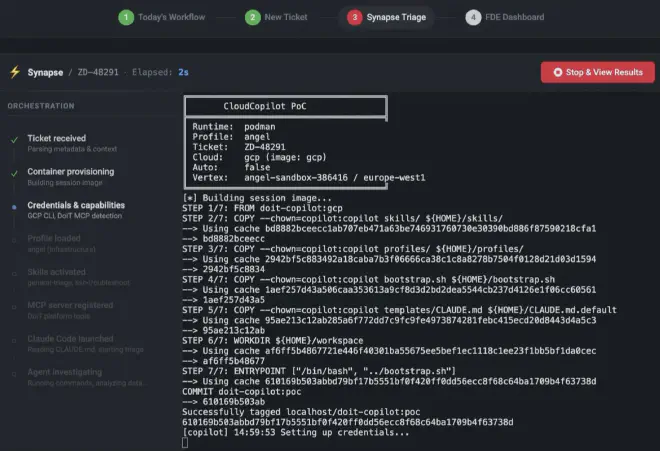
By this point you’re probably wondering what this looks like in practice. In practice it’s a Dockerfile where Claude Code is installed like any other npm dependency, a bootstrap script that detects which tools are available (cloud CLI, internal platform MCP), filters investigation skills by context capabilities, dynamically generates instructions for the agent, and launches it. All the orchestration lives in a bash script and the container layout—not in an agent framework.
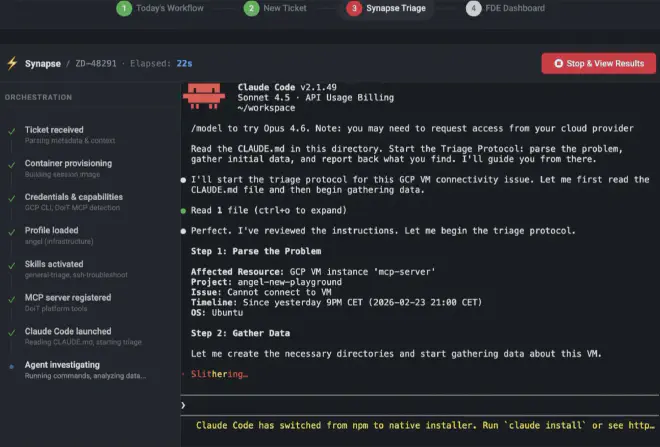
This is where what I consider the most interesting part comes in: context engineering. Dropping Claude Code into a container by itself doesn’t give you a triage agent; it gives you a chatbot with terminal access. What turns that box into something useful is the context you inject. In my setup, the bootstrap dynamically generates a CLAUDE.md tailored to each ticket: who the client is, which cloud they use, which project to investigate, priority, which tools are available, and which triage protocol to follow depending on the operating mode (full, platform-only, or minimal). Each architect also has a profile that defines their specialty and which investigation skills are loaded; those skills in turn declare what capabilities they need, and the bootstrap filters them automatically. This isn’t prompt engineering in the classic “write a good prompt” sense: it’s designing the full cognitive environment the agent operates in. The prompt is just one piece; the real context includes which tools it sees, which playbooks it has, and what ticket and client information arrives already structured.
--ticket ZD-48291 --cloud gcp --profile angel"] subgraph BUILD["Docker image layers"] direction TB BASE["Dockerfile.base
Node.js · Claude Code · DoiT MCP"] CLOUD["Dockerfile.gcp
Google Cloud SDK"] SESSION["Dockerfile
Skills · Profiles · Bootstrap"] BASE --> CLOUD --> SESSION end subgraph MOUNTS["Mounted volumes"] direction LR CREDS["🔒 Credentials :ro"] WORKSPACE["📁 Persistent workspace"] end RUN --> BUILD RUN --> MOUNTS subgraph CONTAINER["📦 Container"] direction TB B1["1. Copy credentials :ro → /tmp/"] B2["2. Detect capabilities
GCP ✓ · AWS ✓ · DoiT MCP ✓"] B3["3. Determine mode
full | doit-only | minimal"] B4["4. Load FDE profile
angel → infrastructure"] B5["5. Filter skills by capabilities"] B6["6. Generate dynamic CLAUDE.md"] B7["7. Register MCP servers"] B1 --> B2 --> B3 --> B4 --> B5 --> B6 --> B7 end BUILD --> CONTAINER MOUNTS --> CONTAINER B7 --> CLAUDE["🤖 Claude Code · Triage agent"] subgraph TOOLS["Available tools"] direction LR GCLOUD["gcloud"] AWSCLI["aws"] MCP["DoiT MCP"] SKILLS["Skills"] end subgraph OUTPUT["Output"] direction LR RAW["./raw/"] FINDINGS["./findings/"] REPORT["TRIAGE_REPORT.md"] end CLAUDE --> TOOLS CLAUDE --> OUTPUT
The concept: disposable minions#
The upshot of all of this is an immutable container that spins up on demand. You pass it a ticket number, read-only cloud credentials, and the Skills and MCP tools it needs. The agent investigates: runs commands, queries the platform, cross-checks data, produces a structured triage report. When it’s done, the container goes away (or not—keep reading for the plot twist).
In my post about GizTUI I talked about the era of disposable code: tools you build, use, and discard. What we’re talking about here is the natural evolution of that idea: disposable cognitive workers. It’s not a far-fetched metaphor—that’s literally what happens. Each instance is immutable, ephemeral, and reproducible. Like a Kubernetes pod, but for intellectual work.
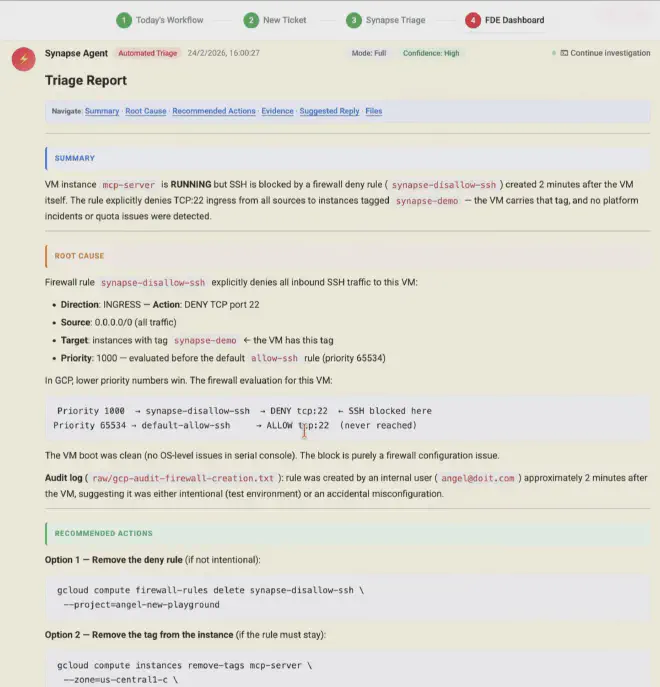
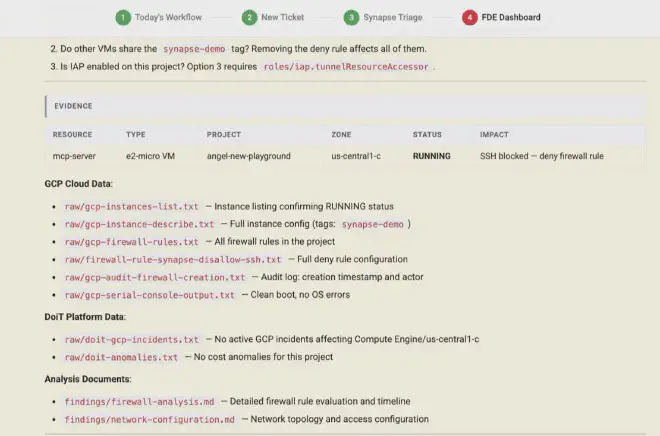
This has some very interesting operational properties. The first is homogeneity: it doesn’t matter which architect runs the container, the environment is identical; you lean on technology that solves “works on my machine”. The AI may be non-deterministic in its answers, but with this approach the environment it runs in is fully controlled and reproducible. The second is auditability: every command run and its output is recorded in the workspace. The third is security, and here there’s a layer worth calling out: investigation credentials are mounted read-only and the agent only has read permissions on the client environment; on top of that, Claude Code lets you configure how you reach the model that powers it. In this case, LLM calls go through Google Cloud’s Vertex AI, so client data never touches the model vendor’s API directly. That decouples your clients’ data from the AI provider and gives you full control over observability and telemetry: you know exactly what’s sent, how many tokens each triage uses, and you can audit everything from your own infrastructure and act when needed. The fourth is scalability: if tomorrow you have fifty P1 tickets at once, you spin up fifty containers and off you go.
Human in the loop: it’s design, not a limitation#
One thing I don’t want to slip by: this isn’t meant to run on autopilot without supervision. Human in the loop isn’t a concession to the current state of the technology (though it is that too) but a conscious design choice. The agent does the heavy lifting of collection and initial analysis; the architect still makes the decisions. They review the report, validate hypotheses, decide next steps.
That’s intentional because the engineer’s real value isn’t in running gcloud compute instances describe but in interpreting what they see, combining it with their experience, and proposing a solution to the client. The minion frees them from two hours of archaeology so they can focus on thirty minutes of expert judgment.
And here’s the plot twist I mentioned earlier: the container doesn’t have to die when the agent finishes its investigation. It can sit there waiting for the architect to connect and resume the session exactly where the agent left off—full context, generated files, and reasoning thread intact. Claude Code supports --resume on an existing session, so the architect joins, sees what the agent did, and can ask it to dig deeper into something or explore an alternative hypothesis. It’s as if the agent left the table set with all the pieces in order. And if you don’t want to keep the original container running, you can persist the session file and bootstrap it in a new one: context travels with state, not with the instance.
So what actually changes?#
If this works—and this first version suggests it does—what changes isn’t just triage speed. What changes is the cost structure of a technical services business. Each architect goes from handling X tickets a day to 3X or 5X, because the mechanical part of investigation is delegated. You don’t need to hire twice as many people to serve twice as many clients. And knowledge doesn’t walk out the door when someone leaves, because investigation playbooks live in the container’s skills, not in anyone’s head.
When I presented this in an internal AI session we run on Thursdays at DoiT, the most interesting reaction didn’t come from the engineers (their eyes were already lit up by the technical nitty-gritty) but from the business side, who immediately saw the implications for margins and scalability.
The open question#
I put all of this together as a proof of concept in two or three days, in short bursts of a few hours each. And I think it’s important to be clear about what this is and isn’t: it’s not a complete production-ready solution. Important pieces are still missing: ephemeral credential management with automatic rotation, formal auditing of the agent’s actions, prompt-injection safeguards, rate limiting, systematic evaluation of triage quality, token cost management at scale, and a more granular permissions model, among others. Each of those has its own complexity and design decisions. The good news is that at DoiT we’re working to turn this vision into a real product, so if there’s interest (and you show it :-p), the decisions we make will be fodder for future posts on how we tackle the move from POC to production.
The question I want to leave on the table, though, isn’t technical. It’s this: what if the future of technical support isn’t hiring more engineers, but giving each engineer their own army of disposable minions to do the heavy lifting? And if so, what skills will actually matter in an engineer when mechanical investigation is done by a machine?
That’s what’s on my mind. If it’s on yours too, let’s talk.